
1.Donut model 로컬에서 실행하기(local execution)
Introduction
“OCR-free Document Understanding Transformer (ECCV 2022)“를 연구의 참고 논문으로 선정했다. 본격적인 연구에 앞서 donut github의 README.md를 기반으로 논문에서 제안한 Donut model을 local에서 돌려보고자 한다.
Setup
1. gitbub repository 복사하기
1.1. clovaai/donut repository를 fork하기
[fork: 다른 사람의 repository를 내 repository로 복사하기]를 참고해서 fork를 한다.

1.2. 복사한 repository를 local에 clone하기
[clone: repository를 내 컴퓨터(local)로 복제하기]를 참고해서 내 계정에 있는 repository를 local에 clone 하고, vscode에 open한다.
2. conda를 이용해 가상환경 설정하기
[가상환경(Virtual Environments)]의 “conda를 이용한 가상환경” 부분을 참고하며, anaconda prompt에서 진행하면 된다.
2.1. 프로젝트 디렉토리로 이동하기
cd [프로젝트 디렉토리 경로]

2.2. 가상환경 생성하기
conda create -n donut_official python=3.7
2.3. 가상환경 활성화하기
conda activate donut_official

2.4. 패키지 설치하기
pip install .는 setup.py 파일을 기반으로 현재 디렉토리의 패키지를 설치하기 위한 명령어이다. setup.py에서 정의된 설정에 따라 패키지를 설치하기 위해 다음과 같은 명령어를 입력하면 된다.
pip install .
3. vscode에서 가상환경 적용하기

Getting started
4. 프로젝트 폴더 확인하기
miscdirectory: README.md에 첨부된 이미지, 데모에 쓸 수 있는 샘플 이미지가 저장되어 있는 디렉토리app.py: Donut 모델을 간편하게 테스트할 수 있는 데모 파일이다. 모델이 어떻게 작동하는지 확인할 수 있다.donutdirectory: Donut 모델의 핵심 기능을 구현한 모듈로, 모델의 encdoer와 decoder를 정의하고, 데이터 전처리, 학습, 평가, 그리고 JSON 데이터 입출력 등 모델의 전반적인 동작을 지원하는 코드들을 포함하고 있다.donut/model.py: Donut 모델의 encoder(Swin Transformer)와 decoder(MBART)를 정의하고, 이미지를 입력받아 구조화된 텍스트(ex: JSON)를 생성하는 전체 모델을 구현한 파일이다. class 형식으로 구현되어 있다.donut/util.py: Donut 모델의 학습 및 평가를 위해 데이터셋을 전처리하고, 예측 결과를 평가하며, JSON 형식의 데이터 입출력 기능을 제공하는 유틸리티 함수 및 클래스를 담고있는 파일이다.donut_python.egg-infodirectory: python 패키지를 설치할 때 생성되는 메타데이터가 포함된 디렉토리이기 때문에 작업할 때 수정할 필요가 없다. 해당 디렉토리 안에requires.txt파일이 있는데 이 파일을 보고 별도로 추가 설치할 필요는 없다.(why? 이전 단계에서pip install .명렁어를 통해 패키지를 설치했을 때requires.txt에 나열된 의존성 패키지들도 함께 설치되었을 것이기 때문임) 만약 실행 시ModuleNotFoundError와 같은 error가 발생한다면,requires.txt파일을 참조하여 필요한 패키지를 수동으로 설치(pip install -r requires.txt)하면 된다.configdirectory: Donut model 학습을 위한 다양한 설정 파일들(.yaml)을 포함하는 디렉토리이다. 이 파일들은 각 작업(CORD, DocVQA, RVL-CDIP, ZH Train Ticket)별로 학습에 필요한 매개변수와 옵션들을 정의하여, 모델 학습 시 해당 설정을 불러와 사용한다.config/train_cord.yaml: CORD 데이터셋을 사용하여 Donut model을 학습할 때 필요한 다양한 설정을 정의한 파일이다. 데이터셋 로드, 학습률, 배치 크기, 입력 이미지 크기 등 학습에 필요한 다양한 매개변수를 포함하고 있고, 이 파일을 사용해 학습을 시작하면 지정된 설정에 따라 모델이 학습을 진행한다.
5. app.py 돌려보기
Donut 모델을 돌리기 위해 어떻게 해야하는지 너무 막막해서, 우선 app.py파일부터 코드를 분석하고 실행시켜보기로 했다.
5.1 주요 코드 분석

5.2 app.py 실행
vscode 상단 메뉴에서 Terminal-New Terminal를 누른 후, 아래에 띄어진 터미널 창에서 Command Prompt를 클릭하여 해당 프롬포트에서 실행하면 된다.
- Document Parsing task를 하기 위해
CORDdataset과 hugging face의donut-base-finetuned-cord-v2trained model을 사용했다.python app.py --task cord --pretrained_path "naver-clova-ix/donut-base-finetuned-cord-v2" - error 발생)
ModuleNotFoundError: No module named 'gradio'가 발생하여,gradio를 설치하고 다시 실행시켰다.pip install gradio - error 발생) Donut model 로드 과정에서 모델이 사전 학습된 가중치를 로드할 때, 가중치 크기와 현재 모델의 구조 사이에 불일치로 인해 오류가 발생했다.
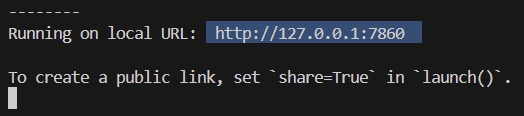
app.py파일의 코드를 다음과 같이 수정했다.pretrained_model = DonutModel.from_pretrained(args.pretrained_path, ignore_mismatched_sizes=True) - 다시 실행했을 때 local url이 뜨면 잘 작동한 것이다. local url을 복사하여 chrome에 접속하여
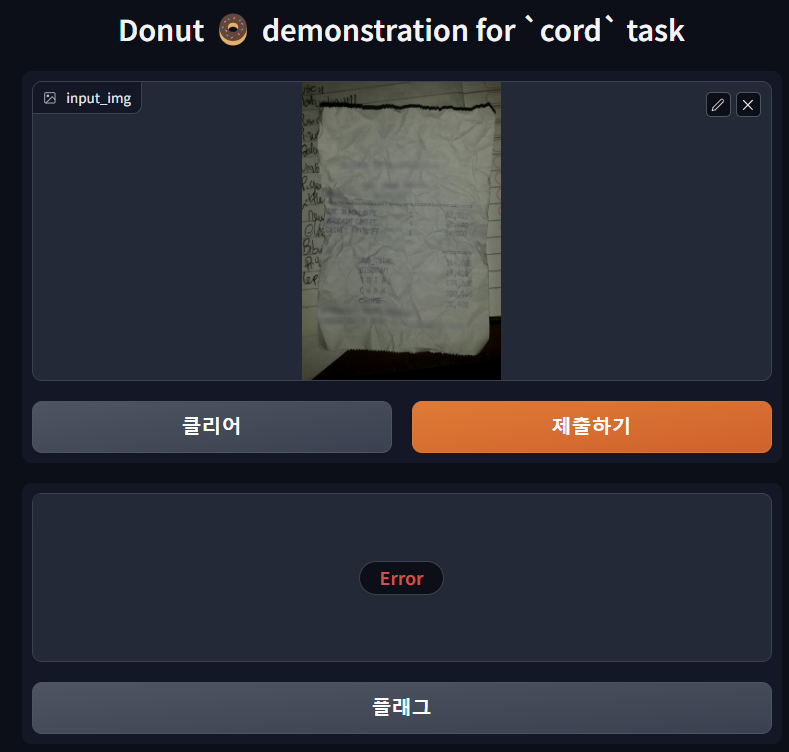
misc에 있는 샘플 영수증 이미지를 업로드했다. 그런데 결과가 error가 떴다. 이는 docvqa로 진행해도 동일한 error가 발생했다.ignore_mismatched_sizes=True설정과 관련된 문제에서 비롯된 것 같다. 우선 해당 오류는 일단은 그냥 넘어가기로 했다.
6. config directory의 .yaml 파일 코드 분석하기
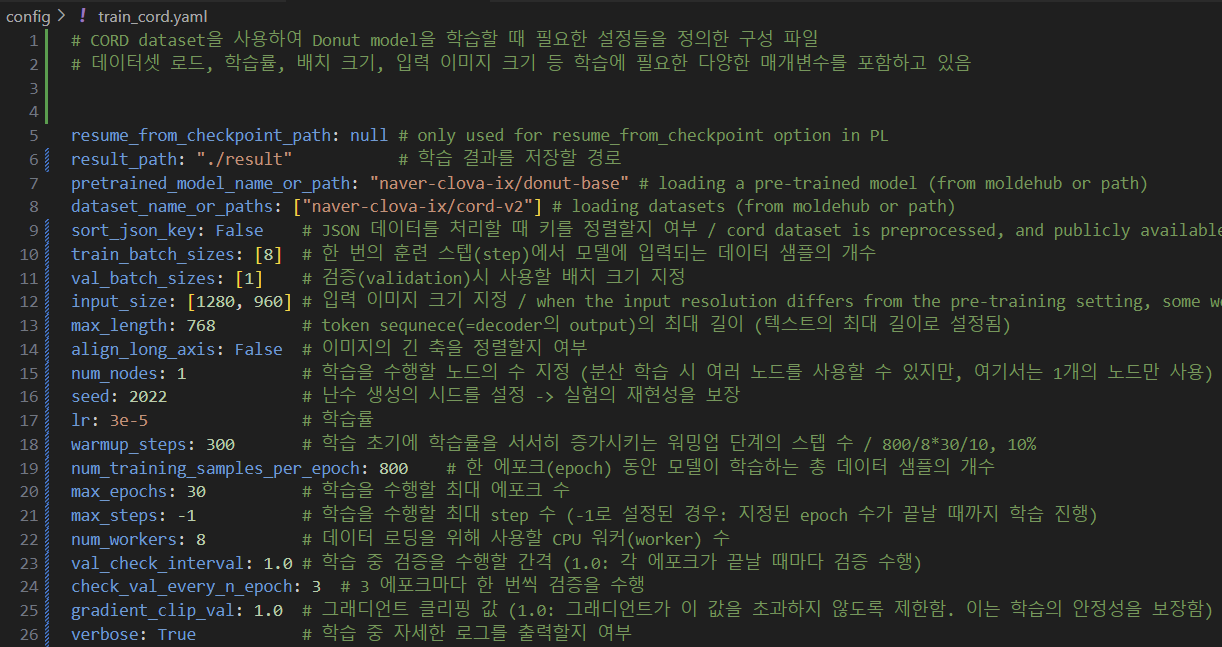
내가 돌려볼 task(document parsing, CORD dataset)에 해당하는 config/train_cord.yaml 파일을 살펴보겠다. 파일 안에서 모델 학습에 중요하거나 이해하는데 애매한 몇 가지 변수들만 설명하겠다.
resume_from_checkpoint_path: null: 이전에 중단된 체크포인트에서 학습을 재개할 경로를 지정한다. 체크포인트란 모델 학습 중에 현재 상태를 저장한 시점을 의미한다. 현재는null로 설정되어 있기 때문에 체크포인트에서 재개하지 않고 처음부터 학습을 시작한다. 다만, 해당 변수는 PyTorch Lightning(PL)의 체크포인트 재개 기능과 관련된 옵션으로, 다른 목적으로 사용되지 않는다. (이 변수는 딱히 중요한 변수는 아니다!)pretrained_model_name_or_path: "naver-clova-ix/donut-base": 사전 학습된 모델을 load할 경로 또는 이름을 지정한다. 여기서"naver-clova-ix/donut-base"는 hugging face model hub에 있는 사전 학습된 Donut model을 의미한다. (donut-proto가 아닌donut-base가 선택된 이유는donut-base가 더 강력한 하드웨어와 더 큰 데이터셋을 사용하여 학습되었기 때문에, 일반적으로 더 좋은 성능을 제공할 가능성이 높음)dataset_name_or_paths: ["naver-clova-ix/cord-v2"]: 학습에 사용할 데이터셋의 이름 또는 경로를 지정한다. 이 변수는 리스트 형식(대괄호 [ ])으로 정의되어 여러 개의 데이터셋을 동시에 지정할 수 있다.train_batch_sizes: [8]: 모델이 한 번의 업데이트(step)에서 사용하는 데이터의 수를 지정한다. 배치 크기(batch size)란 학습 중 한 번의 gradient update(즉, parameter update)를 위해 사용되는 data sample 수이다.num_training_samples_per_epoch: 800: 위의 변수와 의미를 헷갈리기 쉬운 변수이다. 이 변수는 한 epoch 동안 사용할 전체 sample의 수를 지정한다. 이렇게만 들었을 때에는 위의 변수와 무슨 차이인지 와닿지가 않을 것이다. 원래는 한 epoch 동안 전체 데이터셋을 모두 사용해야 하지만, 이 변수를 통해 전체 데이터셋이 아닌, 지정된 수만큼의 샘플만을 사용하도록 설정할 수 있는 것이다.input_size: [1280, 960]: 입력 이미지의 크기를 지정한다. 입력 크기는 모델이 학습할 이미지의 해상도(resolution)를 결정하며, 사전 학습된 모델의 설정과 달라지면 일부 가중치가 새로 초기화될 수 있다. 이 변수 값으로 지정한 해상도는[1280, 960]즉, 1280x960인데, 논문을 보면 pre-trained model의 input resolution(입력 해상도)는 2560x1920으로 설정되어 있다. 이렇게 입력 해상도가 다르기 때문에 CORD dataset을 사용하여 fine-tuning을 할 때 일부 가중치가 새로 초기화될 수 있다. 큰 문제인 것처럼 보일 수 있지만 입력 해상도가 다르더라도 모델 훈련은 가능하다! 그리고 해상도 차이가 너무 크지 않기 때문에 훈련 성능에 있어서도 큰 문제가 되지 않는다.
이외의 변수들에 대한 설명은 다음과 같다.
Train
본격적으로 모델을 학습시키기 위해서는 train.py 파일을 실행시키면 된다. 이 파일은 Donut model을 특정 dataset으로 학습시키는 코드를 담고 있다. PyTorch Lightning을 사용해서 모델을 훈련시키고, 학습 중 다양한 설정과 체크포인트 관리, 로그 기록을 수행한다.
7. train.py 실행시키기
README.md의 Train 파트를 참고하여 진행했다.train.py스크립트를 사용해 CORD dataset에서 Donut model을 훈련시킬 것이다.
vscode의 terminal(cmd)에서 다음과 같이 명령어를 입력한다.
python train.py --config ./config/train_cord.yaml --exp_version "test_experiment"
--config 뒤에 경로는 config directory에 있는 원하는 task에 맞는 .yaml 파일 경로로 설정해주면 된다. CORD dataset으로 학습시키려고 하기 때문에 해당 dataset에 맞는 .yaml 파일 경로를 입력했다. 추가로 --exp_version 옵션을 통해 학습 버전을 지정할 수 있다. 지정하지 않으면 현재 날짜와 시간이 버전으로 사용된다.
8. 오류 해결하기
error 1: ModuleNotFoundError
- 오류 메시지
- tensorboard와 tensorboardX 패키지 설치되지 않아서 발생한 문제였다.
ModuleNotFoundError: Neither `tensorboard` nor `tensorboardX` is available. Try `pip install`ing either. DistributionNotFound: The 'tensorboardX' distribution was not found and is required by the application. HINT: Try running `pip install -U 'tensorboardX'` DistributionNotFound: The 'tensorboard' distribution was not found and is required by the application. HINT: Try running `pip install -U 'tensorboard'`
- tensorboard와 tensorboardX 패키지 설치되지 않아서 발생한 문제였다.
- solution
- tensorboard와 tensorboardX 패키지 설치하기
pip install tensorboard tensorboardX
- tensorboard와 tensorboardX 패키지 설치하기
error 2: lightning_fabric.utilities.exceptions.MisconfigurationException
이 오류는 GPU 설정 관련 오류였다. 논문의 실험은 NVIDIA A100 GPU를 사용하여 실행했다고 github에 언급되어 있지만, A100 GPU를 개인 노트북에서 사용하는 것은 사실상 불가능하기 때문에 실험과 동일한 조건으로 훈련을 진행할 수 없다.
- 오류 메시지
Trainerclass에서devices=0으로 설정되어 있다고 나타났다. 이는 GPU를 사용하려고 하지만,devices=0으로 설정되어 있어서 GPU를 사용할 수 없다는 의미이다.lightning_fabric.utilities.exceptions.MisconfigurationException: `Trainer(devices=0)` value is not a valid input using gpu accelerator.devices변수는Trainerclass에서 모델을 학습시킬 때 사용할 GPU 또는 CPU의 개수를 지정한다.
- solution
- [로컬에서 딥러닝을 위한 GPU 개발환경 구축하기]에서 설명하는 과정을 따라하면 된다.
- 그러나 로컬에서 모델을 돌리는 것은 GPU 문제로 불가능하다고 판단했다.
End
노트북에서 논문의 모델을 돌려보려면 로컬이 아닌 colab에서 실행시켜야 한다는 것을 깨닫게 됐다. .py 파일도 colab에서 실행시킬 수 있기 때문에, colab에서 github와 연동하여 모델을 돌려봐야겠다.
댓글남기기